本文共 11049 字,大约阅读时间需要 36 分钟。
java修饰符
| 修饰符 | 含义 |
|---|---|
| default | |
| public | |
| protected | |
| private | |
| static | |
| final | |
| abstract | |
| synchronized | |
| transient | |
| volatile |
java运算符
| 操作符 | 含义 |
|---|---|
| 算数运算符 | + - * / % ++ – |
| 赋值运算符 | = |
| 关系运算符 | == != > < >= <= |
| & | 对应位都是1,则结果为1,否则为0 |
| | | 对应位都是0,则结果为0,否则为1 |
| ^ | 对应位相同,则结果为0,否则为1 |
| ~ | 按位取反 |
| << | 按位左移 |
| >> | 按位右移 |
| >>> | 按位右移空位补零 |
| 逻辑运算符 | &&(短路) || ! |
| 条件运算符 | ? : |
| instanceof运算符 | 检查该对象是否是一个特定类型 boolean result = name instanceof String; |
运算符优先级
一些常用类
| 类名 | 介绍 |
|---|---|
| Numbers | |
| Math | |
| Character | |
| String | 你一旦创建了 String 对象,那它的值就无法改变了 |
| StringBuffer 和 StringBuilder | StringBuilder 相较于 StringBuffer 有速度优势,但StringBuilder 的方法不是线程安全的(不能同步访问) |
| Date |
JAVA 中的 StringBuilder 和 StringBuffer 适用的场景是什么?
最简单的回答是,stringbuffer基本没有适用场景,你应该在所有的情况下选择使用 stringbuiler,除非你真的遇到了一个需要线程安全的场景,如果遇到了,请务必在这里留言通知我。 然后,补充一点,关于线程安全,即使你真的遇到了这样的场景,很不幸的是,恐怕你仍然有 99.99…99% 的情况下没有必要选择 stringbuffer,因为 stringbuffer 的线程安全,仅仅是保证 jvm不抛出异常顺利的往下执行而已,它可不保证逻辑正确和调用顺序正确。大多数时候,我们需要的不仅仅是线程安全,而是锁。 最后,为什么会有 stringbuffer 的存在,如果真的没有价值,为什么 jdk 会提供这个类?答案太简单了,因为最早是没有stringbuilder 的,sun 的人不知处于何种愚蠢的考虑,决定让 stringbuffer 是线程安全的,然后大约 10年之后,人们终于意识到这是一个多么愚蠢的决定,意识到在这 10 年之中这个愚蠢的决定为 java运行速度慢这样的流言贡献了多大的力量,于是,在 jdk1.5 的时候,终于决定提供一个非线程安全的 stringbuffer 实现,并命名为stringbuilder。顺便,javac 好像大概也是从这个版本开始,把所有用加号连接的 string 运算都隐式的改写成stringbuilder,也就是说,从 jdk1.5 开始,用加号拼接字符串已经没有任何性能损失了。 如诸多评论所指出的,我上面说,"用加号拼接字符串已经没有任何性能损失了"并不严谨,严格的说,如果没有循环的情况下,单行用加号拼接字符串是没有性能损失的,java编译器会隐式的替换成stringbuilder,但在有循环的情况下,编译器没法做到足够智能的替换,仍然会有不必要的性能损耗,因此,用循环拼接字符串的时候,还是老老实实的用 stringbuilder 吧。
java数组
数组可以作为参数传递给方法。数组可以作为函数的返回值。
一维数组
- 声明:
dataType[] arrayRefVar; // 首选的方法dataType arrayRefVar[]; // 效果相同,但不是首选方法 - 创建数组:
arrayRefVar = new dataType[arraySize]; - 数组变量的声明,和创建数组可以用一条语句完成,如下所示:
dataType[] arrayRefVar = new dataType[arraySize];或dataType[] arrayRefVar = {value0, value1, ..., valuek}; - 当处理数组元素时候,我们通常使用基本循环或者 For-Each 循环:
for(type element: array){ System.out.println(element);} 多维数组
- 直接为每一维分配空间,格式如下:
type[][] typeName = new type[typeLength1][typeLength2]; - 从最高维开始,分别为每一维分配空间,例如:
String s[][] = new String[2][]; s[0] = new String[2];s[1] = new String[3];s[0][0] = new String("Good");s[0][1] = new String("Luck");s[1][0] = new String("to");s[1][1] = new String("you");s[1][2] = new String("!"); Arrays 类
- java.util.Arrays 类能方便地操作数组,它提供的所有方法都是静态的。
| 方法 | 说明 |
|---|---|
| public static int binarySearch(Object[] a, Object key) | 用二分查找算法在给定数组中搜索给定值的对象(Byte,Int,double等)。数组在调用前必须排序好的。如果查找值包含在数组中,则返回搜索键的索引;否则返回 (-(插入点) - 1)。 |
| public static boolean equals(long[] a, long[] a2) | 如果两个指定的 long 型数组彼此相等,则返回 true。如果两个数组包含相同数量的元素,并且两个数组中的所有相应元素对都是相等的,则认为这两个数组是相等的。换句话说,如果两个数组以相同顺序包含相同的元素,则两个数组是相等的。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
| public static void fill(int[] a, int val) | 将指定的 int 值分配给指定 int 型数组指定范围中的每个元素。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
| public static void sort(Object[] a) | 对指定对象数组根据其元素的自然顺序进行升序排列。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
- 数组容量如果不够用可以使用 Arrays.copyOf() 进行扩容:
Array.copy(E[] e,newLength);其第一个形参指的是需要扩容的数组,后面是扩容后的大小, 其内部实现其实是使用了 System.arrayCopy(); 在内部重新创建一个长度为 newLength 类型是 E 的数组。
一些应用
- 实现数组和字符串的转换处理:
public class Test { public static void main(String args[]) { String str = "helloworld"; char[] data = str.toCharArray();// 将字符串转为数组 for (int x = 0; x < data.length; x++) { System.out.print(data[x] + " "); data[x] -= 32; System.out.print(data[x] + " "); } System.out.println(new String(data)); }} - 只能存放同一类中的数据
int[] arr = { 'a', 25, 45, 78, 'z' };System.out.println(Arrays.toString(arr)); 输出结果是:[97, 25, 45, 78, 122]
正则表达式
java.util.regex 包主要包括以下三个类:
- Pattern 类: pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
- Matcher 类: Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
- PatternSyntaxException类: PatternSyntaxException是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
捕获组
- 捕获组是把多个字符当一个单独单元进行处理的方法,它通过对括号内的字符分组来创建。
- 捕获组是通过从左至右计算其开括号来编号。
- 可以通过调用 matcher 对象的 groupCount 方法来查看表达式有多少个分组。groupCount 方法返回一个 int 值,表示matcher对象当前有多个捕获组。
- 还有一个特殊的组(group(0)),它总是代表整个表达式。该组不包括在 groupCount 的返回值中
Match类
索引方法
研究方法 替换方法一些应用
- 校验QQ号,要求:必须是5~15位数字,0不能开头。
public class regex { public static void main(String[] args) { checkQQ2("0123134"); } public static void checkQQ2(String qq) { String reg = "[1-9][0-9]{4,14}"; System.out.println(qq.matches(reg)?"合法qq":"非法qq"); }} 方法
可变参数
方法的可变参数的声明:typeName... parameterName
finalize() 方法
Java 允许定义这样的方法,它在对象被垃圾收集器析构(回收)之前调用,这个方法叫做 finalize( ),它用来清除回收对象。
finalize() 一般格式是:protected void finalize(){ // 在这里终结代码} public class FinalizationDemo { public static void main(String[] args) { Cake c1 = new Cake(1); Cake c2 = new Cake(2); Cake c3 = new Cake(3); c2 = c3 = null; System.gc(); //调用Java垃圾收集器 } } class Cake extends Object { private int id; public Cake(int id) { this.id = id; System.out.println("Cake Object " + id + "is created"); } protected void finalize() throws java.lang.Throwable { super.finalize(); System.out.println("Cake Object " + id + "is disposed"); } } 运行以上代码,输出结果如下:
$ javac FinalizationDemo.java
$ java FinalizationDemo Cake Object 1is created Cake Object 2is created Cake Object 3is created Cake Object 3is disposed Cake Object 2is disposed输入输出
如果要输入 int 或 float 类型的数据,在 Scanner 类中也有支持,但是在输入之前最好先使用 hasNextXxx() 方法进行验证,再使用 nextXxx() 来读取:
import java.util.Scanner; public class ScannerDemo { public static void main(String[] args) { Scanner scan = new Scanner(System.in);// 从键盘接收数据 System.out.println("next方式接收:"); if (scan.hasNext()) { // 判断是否还有输入 String str1 = scan.next(); System.out.println("输入的数据为:" + str1); } System.out.println("nextLine方式接收:"); if (scan.hasNextLine()) { // 判断是否还有输入 String str2 = scan.nextLine(); System.out.println("输入的数据为:" + str2); } scan.close(); }} next() 与 nextLine() 区别:
next(): 1、一定要读取到有效字符后才可以结束输入。 2、对输入有效字符之前遇到的空白,next() 方法会自动将其去掉。 3、只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符。 next() 不能得到带有空格的字符串。 nextLine(): 1、以Enter为结束符,也就是说 nextLine()方法返回的是输入回车之前的所有字符。 2、可以获得空白。
异常
4、throw跟throws的区别:
public void test() throws Exception { throw new Exception(); } 从上面这一段代码可以明显的看出两者的区别。throws表示一个方法声明可能抛出一个异常,throw表示此处抛出一个已定义的异常(可以是自定义需继承Exception,也可以是java自己给出的异常类)。5、接下来看一下如何捕获异常:
1)首先java对于异常捕获使用的是try—catch或try — catch — finally 代码块,程序会捕获try代码块里面的代码,若捕获到异常则进行catch代码块处理。若有finally则在catch处理后执行finally里面的代码。然而存在这样两个问题:
a.看如下代码: try{ //待捕获代码 }catch(Exception e){ System.out.println(“catch is begin”); return 1 ; }finally{ System.out.println(“finally is begin”); } 在catch里面有一个return,那么finally会不会被执行呢?答案是肯定的,上面代码的执行结果为: catch is begin finally is begin 也就是说会先执行catch里面的代码后执行finally里面的代码最后才return1 ;b.看如下代码:
try{ //待捕获代码 }catch(Exception e){ System.out.println(“catch is begin”); return 1 ; }finally{ System.out.println(“finally is begin”); return 2 ; } 在b代码中输出结果跟a是一样的,然而返回的是return 2 ; 原因很明显,就是执行了finally后已经return了,所以catch里面的return不会被执行到。也就是说finally永远都会在catch的return前被执行。(这个是面试经常问到的问题哦!)6、对于异常的捕获不应该觉得方便而将几个异常合成一个Exception进行捕获,比如有IO的异常跟SQL的异常,这样完全不同的两个异常应该分开处理!而且在catch里处理异常的时候不要简单的e.printStackTrace(),而是应该进行详细的处理。比如进行console打印详情或者进行日志记录。
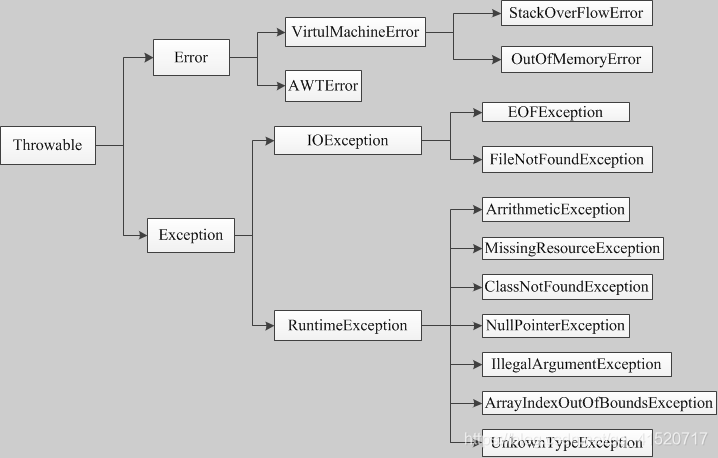
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。- 所有的异常类是从 java.lang.Exception 类继承的子类。
- Exception 类是 Throwable 类的子类。除了Exception类外,Throwable还有一个子类Error 。Java程序通常不捕获错误。错误一般发生在严重故障时,它们在Java程序处理的范畴之外。Error 用来指示运行时环境发生的错误。例如,JVM内存溢出。一般地,程序不会从错误中恢复。
- 异常类有两个主要的子类:IOException 类和 RuntimeException 类。
名词解释 :
1、检查性异常: 不处理编译不能通过 2、非检查性异常:不处理编译可以通过,如果有抛出直接抛到控制台 3、运行时异常:就是非检查性异常 4、非运行时异常: 就是检查性异常
捕获异常
使用 try 和 catch 关键字可以捕获异常。try/catch 代码块放在异常可能发生的地方。try/catch代码块中的代码称为保护代码,使用 try/catch 的语法如下:
try{ // 程序代码}catch(ExceptionName e1){ //Catch 块}finally{ // 程序代码} throws/throw 关键字
- 如果一个方法没有捕获到一个检查性异常,那么该方法必须使用 throws 关键字来声明。throws 关键字放在方法签名的尾部。
- 也可以使用 throw 关键字抛出一个异常,无论它是新实例化的还是刚捕获到的。
- 一个方法可以声明抛出多个异常,多个异常之间用逗号隔开。
import java.io.*;public class className{ public void withdraw(double amount) throws RemoteException, InsufficientFundsException { // Method implementation throw new RemoteException(); } //Remainder of class definition} 声明自定义异常
- 所有异常都必须是 Throwable 的子类。
- 如果希望写一个检查性异常类,则需要继承 Exception 类。
- 如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
通用异常
在Java中定义了两种类型的异常和错误。
- JVM(Java虚拟机) 异常:由 JVM 抛出的异常或错误。例如:NullPointerException类,ArrayIndexOutOfBoundsException 类,ClassCastException 类。
- 程序级异常:由程序或者API程序抛出的异常。例如 IllegalArgumentException类,IllegalStateException 类。
继承
需要注意的是 Java 不支持多继承,但支持多重继承。
继承的特性:
1.子类拥有父类非 private 的属性、方法。 2.子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。 3.子类可以用自己的方式实现父类的方法。 4.Java 的继承是单继承,但是可以多重继承。 5.提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)。
- 继承可以使用 extends 和 implements 这两个关键字来实现继承,extends 只能继承一个类,使用 implements关键字可以变相的使java具有多继承的特性。
- 所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承object(这个类在 java.lang 包中,所以不需要import祖先类。
- super关键字:我们可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。
- this关键字:指向自己的引用。
- final 关键字声明类可以把类定义为不能继承的,即最终类;或者用于修饰方法,该方法不能被子类重写
- 子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式)。如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
- 子类的所有构造方法内部, 第一行会(隐式)自动先调用父类的无参构造函数super();执行父类构造函数的语句只能放在函数内语句的首句,不然会报错
父类引用指向子类对象,而子类引用不能指向父类对象。
把子类对象直接赋给父类引用叫upcasting向上转型,向上转型不用强制转换吗, 把指向子类对象的父类引用赋给子类引用叫向下转型(downcasting),要强制转换
子类不能直接继承父类中的 private 属性和方法。
/**建立一个公共动物父类*/public class Animal { private String name; private int id; /*由于name和id都是私有的,所以子类不能直接继承, 需要通过有参构造函数进行继承*/ public Animal(String myname,int myid) { name = myname; id = myid; } public void eat() { System.out.println(name+"正在吃"); } public void sleep() { System.out.println(name+"正在睡"); } public void introduction() { System.out.println("大家好!我是" +id+"号"+name +"."); }}子类 Penguin 需要通过关键字 super 进行声明public class Penguin extends Animal { public Penguin(String myname,int myid) { super(myname,myid); // 声明继承父类中的两个属性 }}具体通过有参构造函数进行继承。public class PenguinQQ { public static void main(String[] args) { // TODO Auto-generated method stub Penguin QQ = new Penguin("小冰",10086); //调用一个有参构造方法 QQ.eat(); QQ.sleep(); QQ.introduction(); }} 接口:抽象方法的集合
组织
package
import 类目录的绝对路径叫做 class path。设置在系统变量 CLASSPATH 中。转载地址:http://sbqen.baihongyu.com/